Saturday, December 24, 2011
Some Christmas Cheer.....
We all know that the Euro is going down and quite possibly the EU with it. After we've all recharged out batteries over Christmas though, let's be sure to give it a helping hand in the New Year:
Saturday, November 26, 2011
Churnalism: DEFRA churn - the Guardian is in the lead!
(UPDATE: 27/11/11 - raw churnalism data available HERE - JSON format, zipped, 448kb)
After the churn analysis of the Environment Agency press releases (please read that article for more details and important caveats if you haven't read one of my churn posts before), I followed up with DEFRA.I will be making the raw data publicly available tomorrow for both the Environment Agency and DEFRA churn analyses.
This time I was able to construct the spiders and process the data faster - I also avoided (most of) the unicode problems that plagued me with the EA data, so this analysis can be considered slightly more accurate and slightly less forgiving of the media organisations (though it still strictly follows the rules I set down previously, such as no editing of the press release to remove extraneous information). Along with inevitable issues with some difficult characters slipping through and no editing of the press releases, it still means the data will naturally favour the media organisations. As I said on previous posts, when I make the raw data publicly available, churn analysis by other people will very likely improve upon my methods and yield results more detrimental for the media.
In any case - onto the results. The summary is presented below (click for full size image):
Summary of results:
- A total of 386 press releases were analysed, from 13th May 2010 to 24th November 2011. These generated 1959 detectable cases of churn. Again, there is probably a lot of interesting data within the "detectable" category that deserves analysis at a later date. For now it is discarded.
- Out of those, 173 were classified as "significant" and 18 as "major".
- The Guardian was the leader in both categories by a long way - accounting for 19.65% of significant churn and 27.78% of major churn.
- The BBC followed close behind in terms of significant churn with 16.18%, though for major churn was beaten into third place by both the Independent and the Daily Mail with a joint 16.67%.
- The Independent came third in the signifcant churn classification.
- A common factor in the most highly churned articles both in this analysis and the previous two appears to be lack of a named author in most cases (though see one of the exceptions detailed below). This suggests the media organisations are aware that what they are doing is not kosher.
- Continuing a theme from the last two churn analyses, the tabloids consistently embarrass the so called "quality press". This time I pulled out the statistics for the UK's major tabloids for comparison (click for full size image):
When I first started these analyses I fully expected to see a much higher showing of churn by the tabloids. It is interesting to see the contrast. Also out of the churn analyses done so far, it is consistently the Mirror out of the tabloids that has the highest percentage of churn.
As usual I select a few of the more egregarious cases of churn for your entertainment (and importantly - provide a manual submission to the churnalism database so they can be seen visually):
'Gloucestershire Old Spots pork protected by Europe'
An absolutely cracking BBC 79% cut and paste job on - er - crackling.
'Bonfire of the Quangos'
Remember that list of Quangos that were to go? Completely cut and pasted from a press release. This one is particularly fascinating because in the two worst cases the cut and paste was the list provided in the press release. It actually included several paragraphs laying out a context that was not cut and pasted across. If it had just been the list in the original both would have scored close to 100% pastes.....
The pastes are so large in any case that the churnalism engine falls over when the 'view' button is clicked to see the visualised version. Be warned if you click it, your browser may hang.
'New service for householders to stop unwanted advertising mail'
Absolute carnage on the churning front here with the majority of the main media outlets represented. The Guardian appeared to like this story so much they cut and pasted it twice - and this time each article has a named author. Where the hell was the editor?
After the churn analysis of the Environment Agency press releases (please read that article for more details and important caveats if you haven't read one of my churn posts before), I followed up with DEFRA.I will be making the raw data publicly available tomorrow for both the Environment Agency and DEFRA churn analyses.
This time I was able to construct the spiders and process the data faster - I also avoided (most of) the unicode problems that plagued me with the EA data, so this analysis can be considered slightly more accurate and slightly less forgiving of the media organisations (though it still strictly follows the rules I set down previously, such as no editing of the press release to remove extraneous information). Along with inevitable issues with some difficult characters slipping through and no editing of the press releases, it still means the data will naturally favour the media organisations. As I said on previous posts, when I make the raw data publicly available, churn analysis by other people will very likely improve upon my methods and yield results more detrimental for the media.
In any case - onto the results. The summary is presented below (click for full size image):
 |
| "Quality" press churn results |
Summary of results:
- A total of 386 press releases were analysed, from 13th May 2010 to 24th November 2011. These generated 1959 detectable cases of churn. Again, there is probably a lot of interesting data within the "detectable" category that deserves analysis at a later date. For now it is discarded.
- Out of those, 173 were classified as "significant" and 18 as "major".
- The Guardian was the leader in both categories by a long way - accounting for 19.65% of significant churn and 27.78% of major churn.
- The BBC followed close behind in terms of significant churn with 16.18%, though for major churn was beaten into third place by both the Independent and the Daily Mail with a joint 16.67%.
- The Independent came third in the signifcant churn classification.
- A common factor in the most highly churned articles both in this analysis and the previous two appears to be lack of a named author in most cases (though see one of the exceptions detailed below). This suggests the media organisations are aware that what they are doing is not kosher.
- Continuing a theme from the last two churn analyses, the tabloids consistently embarrass the so called "quality press". This time I pulled out the statistics for the UK's major tabloids for comparison (click for full size image):
 |
| Tabloid press churn results |
As usual I select a few of the more egregarious cases of churn for your entertainment (and importantly - provide a manual submission to the churnalism database so they can be seen visually):
'Gloucestershire Old Spots pork protected by Europe'
An absolutely cracking BBC 79% cut and paste job on - er - crackling.
'Bonfire of the Quangos'
Remember that list of Quangos that were to go? Completely cut and pasted from a press release. This one is particularly fascinating because in the two worst cases the cut and paste was the list provided in the press release. It actually included several paragraphs laying out a context that was not cut and pasted across. If it had just been the list in the original both would have scored close to 100% pastes.....
The pastes are so large in any case that the churnalism engine falls over when the 'view' button is clicked to see the visualised version. Be warned if you click it, your browser may hang.
'New service for householders to stop unwanted advertising mail'
Absolute carnage on the churning front here with the majority of the main media outlets represented. The Guardian appeared to like this story so much they cut and pasted it twice - and this time each article has a named author. Where the hell was the editor?
Friday, November 25, 2011
It's mob rule at the Guardian....

There's nothing quite like rank hypocrisy to boil my piss. However, to ensure it is fully evaporated in anger, combine rank hypocrisy with crass stupidity, naked opportunism, complete resistance to facts or reason and censorship.
For that was the bread and butter of Leo "bless 'im" Hickman's disgraceful piece of yellow bellied journalism at the Guardian today.
Hickman decided it was time to form a posse comitatus to try tracking down the source of the climategate emails, laughably using the README textfile included in the latest tranche of releases as the primary source of evidence.
This was one of those pieces - especially as it was in the comment is free if you agree section - that really reveals the Guardian's true colours. Numerous commentators including me (prior to the first round of censorship - sorry - 'comment adjustment') attempted to point out the Guardian's and Hickman's rank hypocrisy on this issue. The most striking and obvious example having been the paper's massive support for Wikileaks, however there were many other examples, including the anonymous Enron whistleblower, as another commenter pointed out. As was repeated again and again, it appeared that all leakers were equal but some were more equal than others in the Guardian's eyes.
This was of course brushed off by Hickman and his part-time principle party of followers in the comments section.
Next I pointed out (prior to 'comment adjustment') that claiming it was the work of a hacker was still just an assumption. Hickman replied to me directly on that and similarly brushed it off. He claimed it was irrelevant. The poor dear didn't seem to realise that if he assumed it was the work of a hacker and in fact it was a leaker then his "investigation" would lead him down to all sorts of blind alleys, not least because the MO and levels of access would be completely different (not to mention the trail of evidence left behind).
There were a plethora of delightfully dense comments in support of Hickman et al and stunning leaps of reasoning. These people were also apparently immune to criticism because they "knew" what they were claiming was true, especially regarding the "hacker" claim. Many pronounced completely ill-informed statements about this showing that i) they knew nothing about IT security and ii) that they couldn't even be bothered to use google to check details. After all, The difference between an internal security breach and a carefully coordinated external breach is vast. Pointman gave an excellent overview after the first climategate - here. Moreover they absolutely did not care about their ignorance. What a familiar pattern, eh? No wonder they were immediately supportive of the "scientists" at the heart of the climategate storm - they're just like them!
There were some absolute crackers amongst the received wisdom of this bunch of easily led zealots and I highly recommend you read through the comments - well those that are left - as it is a laugh a minute.
Komment Macht Frei
Speaking of the comments - when the piece first appeared this morning, it was absolute devastation from the moderator. ALL of my comments bar the first one were censored, as were numerous other comments by others. I had no clue why they'd been removed beyond the fact that we all seemed to disagree intensely with Hickman.

Now bizaarely, after the comments spilled over onto two pages I happened to click back to the first page to see what else had been censored and was surprised to see that most of my previously "moderated" comments had reappeared (except for the "nuked" ones). I don't know if this is a bug in their software or a disagreement between moderators but it adds even more to the general sense of confusion and latent fear of arbitrary censorship that completely fucks any meaningful contribution over there.
Another important point to be aware of is this: One way to guarantee being censored on the Guardian is if you make a reference to your, or someone else's having been censored you will immediately be censored and they often use the "nuke" option too.
The Guardian is - as a media institution - utterly reprehensible. Most other media outlets are of course too, across the political spectrum. But none outside the BBC attempt to present themselves so often as the default "good guys", nor do their followers similarly regard it as received wisdom...
The climategate 'gait' or the 'out of context paradox'
There's a regular pattern that occurs in any discussion of climategate (1 or 2). It is inconsistent but also entirely consistent with the unthinking nature of many of those who promulgate it:
i) They assert that the emails were "taken out of context"
ii) Responder says that they are not.
iii) A request is then made for evidence.
iv) Responder invites them to read the emails - there are numerous complete email chains, supporting claims against the "scientists" that ONLY MAKE SENSE IN CONTEXT. But the trick is you have to actually read the emails....
 |
| A modern day climate "scientist" |
One final delicious irony of this of course is that 'The Team' will surely be scratching their heads now, trying to remember what on earth what was said to who. But because they very likely deleted these emails after they had been copied from the mailserver then they have only one place to go to check.....
Friday, November 18, 2011
Sometimes humour is the only weapon left....
....and the most appropriate to get the point across:

(click picture to see full size version)
Story here.

(click picture to see full size version)
Story here.
Friday, November 11, 2011
They Shall Not Grow Old

Those of us in generations 'jones','x' and 'millennial' will be the last to have known veterans from either of the World Wars. Something about that fact makes me profoundly sad, although I'm not entirely sure why. I think part of it may be to do with the fact that it only took 10 years for the upcoming generations that will follow us to forget who Osama Bin Laden was.....
In Flanders fields the poppies blow
Between the crosses, row on row,
That mark our place; and in the sky
The larks, still bravely singing, fly
Scarce heard amid the guns below.
We are the dead. Short days ago
We lived, felt dawn, saw sunset glow,
Loved, and were loved, and now we lie
In Flanders fields.
Take up our quarrel with the foe:
To you from failing hands we throw
The torch; be yours to hold it high.
If ye break faith with us who die
We shall not sleep, though poppies grow
In Flanders fields. – Lt.-Col. John McCrae

Monday, October 31, 2011
Remember, remember...

...its time again for the annual November 5th walk with Old Holborn and the rest of us assorted libertarian ne'er do wells. As Witterings from Witney says - it falls on a Saturday this time, so no excuses - be there!
Its always good fun and brings out quite a few interesting people you might want to meet!
Hopefully we won't get section 44ed like we did the first time....
Tuesday, September 27, 2011
People ask me why I don't trust the media...[Warning: Potty Mouth Post....]

HERE is why.
Be prepared for truly colossal weapons-grade fuckwittery.
"Here’s an upload of a video from a recent ITV documentary into Colonel Gaddhafi’s support of the IRA. It contains shocking footage of a helicopter being shot down using weapons allegedly supplied by that baddie.
Except. Umm. It’s actually ArmA 2." [A COMPUTER GAME]
Do go and read the whole thing. Your blood pressure will shoot up right about the point where the likely provenance of the video is pointed out.
ITV - if brains were dynamite, you wouldn't have enough to blow your fucking hat off. Unfortunately your Stupid is only the apex of the current media-class general cockpuppetfuckwittery.
I used to find the film 'Idiocracy' funny. I don't anymore.
Saturday, June 11, 2011
About that global warming......
....the catastrophic prophecies of climate disaster require an essential ingredient that all too often is completely missing in debates on the subject: positive water vapour feedback. Without increasing amounts of water vapour in the atmosphere (being a much more powerful GHG than CO2), allegedly as a result of human contributed CO2 (in reality, something that could be caused by any heating mechanism), then any catastrophic predictions are bunk. Period.
 (Click for larger version)
(Click for larger version)
Over 50 years of data with no sign of the fabled feedback.
And yet we continue to do this to ourselves.
When enough people forced into penury and suffering realise the source of their misery, email death threats are going to be the last thing the catastrophist "scientists" will have to worry about.
 (Click for larger version)
(Click for larger version)Over 50 years of data with no sign of the fabled feedback.
And yet we continue to do this to ourselves.
When enough people forced into penury and suffering realise the source of their misery, email death threats are going to be the last thing the catastrophist "scientists" will have to worry about.
Wednesday, June 01, 2011
The Rights of Wonga
 No not money itself, the company that loans it out.
No not money itself, the company that loans it out.Wonga.com have come in for a significant amount of flak for their business practices. I have to admit, I gawped as soon as I saw the interest rate of a whopping 4,214% typical APR. I initially shrugged it off as a business that would only appeal to the most desperate of people.
However, the creators of the business gave an interview to the UK edition of Wired this month and they have a lot of interesting points to make. None of which are likely to escape the techno-fanboy realm of Wired; and they certainly won't make it into the pages of the likes of the Guardian.
Wonga argue that they are disrupting what has fundamentally been a monolithic monopoly market by providing small, short term loans. Something that the current banking sector in the UK simply does not service. In the interview the creators claim that customers want three things from such a service: "Firstly, simplicity - the ability to borrow what they want, when they want. Secondly, speed - the transaction needs to happen fast. Thirdly, they want to know exactly and clearly what the loan is going to cost them whether they pay on time, pay early or even miss their deadline."
Banks, they argue, have no incentives to meet these needs. Internet technologies however make all three perfectly servicable.
Errol Damelin (one of Wonga's creator) even goes on to make the oft-made by libertarians, rarely-heard by others, corporatist point: "Banks love regulation. They have been better than anyone else at co-opting it to suit themselves. They love embedding themselves into the messy greyness of how policy is created. And that makes it harder for them to innovate. They're all wink-wink. They don't compete. When did you last hear of a bank competing to bring down the cost of CHAPS payments? When was the last time you saw an interesting new Barclays product? I don't think ever."
And looking at the figures Wonga no longer seems so bad or as exploitative as their detractors have made out. Despite the horrifying interest rate, in practice it would mean a loan of £400 repayable over 30 days would come to £525.48. I've occasionally been up the proverbial creek because an employer has screwed up my pay and my rent and bills are due the next day. I can certainly see occasions where Wonga's services could have been useful in the past and in today's increasingly hand-to-mouth economy I can see why other people might have cause to use them too.
The position is that they are not exploiting people, but providing a service to a generation that has had expectations of flexibility and speed for some time in this sector that simply are not met.
Damelin puts its utility this way in the interview: "We do small, short-term things, and the cost of delivering that service is high.....Catching a cab might be expensive, but it's convenient and nobody complains that being charged £15 for getting across London is immoral."
And the competition?
It gets more interesting: In order to provide an incredibly fast turnaround for their loans, Wonga have opted to have sameday loan applications processed solely by their algorithm. You read that right. No human input.
Their algorithm uses a bespoke method of credit scoring that learns from previous transactions. I, and many others it seems, supposed that the business must have a high default rate. Initially they used the same credit scoring methods as the rest of the finance industry, leading to a 50% default rate from the customers who were being granted loans. However as they moved away from this system and onto their own algorithm, the default rate dropped to single figures (they refuse to release the exact figure however they claim that it is industry leading). The typical default rate assumed by banks is 10%.
This means that despite being in the most high-risk financial sector Wonga are outperforming the high-street banks. They speculate that they could possibly do the same for consumer banking. It's an interesting thought that such an upstart could seriously challenge the retail banking monopolies isn't it?
Your virtual body of evidence
In amongst the innovations and the counterpoints to the bad press Wonga have got there is an important warning. One that our errant media has failed to note: Wonga's nearest competitor, U.S. based prosper.com process all of their applications manually and yet end up with a 40% default rate. Wonga's algorithm works on up to approximately 30 pieces of information initially supplied by the applicant and then finds a further "6,000 to 8,000 online data points that relate to the applicant".
 Wonga won't say what those data points are, so one is immediately drawn to asking what they must be. Social media will definitely be a large factor (there exists a similar facility named Duedil that harvests social media such as LinkedIn to assess the soundness of companies for example...), which means an enormous amount of people are revealing patterns in their online data that they are probably not aware of themselves. This is a recurring theme in my own research - finding and helping people to expose such patterns, with the normative judgement that people should have access to their own data - and patterns - to enable them to be self-aware enough to avoid being manipulated by others who hold that knowledge. Wonga have mastered these techniques to the point of being able to create a multi-million pound turnover on the back of it, which means the data and the patterns hidden within are of significant value.....
Wonga won't say what those data points are, so one is immediately drawn to asking what they must be. Social media will definitely be a large factor (there exists a similar facility named Duedil that harvests social media such as LinkedIn to assess the soundness of companies for example...), which means an enormous amount of people are revealing patterns in their online data that they are probably not aware of themselves. This is a recurring theme in my own research - finding and helping people to expose such patterns, with the normative judgement that people should have access to their own data - and patterns - to enable them to be self-aware enough to avoid being manipulated by others who hold that knowledge. Wonga have mastered these techniques to the point of being able to create a multi-million pound turnover on the back of it, which means the data and the patterns hidden within are of significant value..... Point someone to this blog entry next time someone questions you as to why you don't want the state gathering more information on you than you want it to....
Tuesday, May 24, 2011
One Ring to rule them all...
 Today a debate took place in parliament regarding an absolutely crucial issue for the future of the UK and the financial well-being of its citizens: Mark Reckless MP proposed an anti-bailout motion that would have been the first strong anti-Euro (and with it - anti EU) sentiment expressed by the house in decades.
Today a debate took place in parliament regarding an absolutely crucial issue for the future of the UK and the financial well-being of its citizens: Mark Reckless MP proposed an anti-bailout motion that would have been the first strong anti-Euro (and with it - anti EU) sentiment expressed by the house in decades.Many a strong word was spoken in the chamber earlier against the EU by many of the handful (circa 50) present - and by MPs from both sides of the aisle. For once I actually felt proud of the MPs participating, and I recommend you watch the debate on iplayer, or read the proceedings in Hansard tomorrow. It was such a sharp contrast to the puppet show that passes for the Prime Minister's Question time and I had to fancy what Parliament would be like if these individuals occupied the front benches instead of the back.
Yet how many of those words will be carried by our ever useless peon media to the the ears and eyes of the masses? Instead the media will be perhaps focused on some prat who sought injunctions against revealing a relationship with a woman trying to extort him (and try finding *that* latter fact reported in the media....they would have known had they actually read the linked document....).
However this pleasant fantasy of a functioning representative democracy was soon blown to pieces as I remembered how Daniel Hannan had detailed the "wrecking amendment" put forward.
It didn't matter what the attendees actually said. The whips ensured another 250 MPs turned up to guarantee it was the amended version that went through and not the original motion, turning what was a strongly worded motion into a wet-through general statement of discontent that the government can safely ignore.
I sometimes find it difficult containing my anger over such shenanigans in parliament - regarding how easily results can be 'fixed' in this fashion. I don't remember sleeping in and missing the vote for which whips I wanted. Do you? And I find it intolerable that the people who both proposed the wrecking amendment and voted are not obliged to participate in the debate.
The People's Pledge valiantly attempted to encourage people to write to their MPs beforehand to ask them to vote against the amendment. Would that doing so have had any effect in any case where the majority of MPs are concerned. Aside from the whipped MPs I note, with utter disgust, that ALL of the MPs from Sheffield (which has been my home for far too long now...) failed to even turn up to either the debate or the vote. So much for the salt-of-the-earth Labour MPs standing up for the working man and woman, eh? My current MP, Mr. Paul "I ran Sheffield University Student's Union" Blomfeld, ignored my letter on the topic - as indeed he has done with the last few letters sent to him.
(UPDATE: One of my friends has just informed me that however that "Blomfield did manage to find the time to attend a drinks reception for Sheffield Union officers")
The final vote was 267 to 46. Had it been just those present for the debate voting I am confident the original motion, not the amended version, would have been carried. Such is our utterly dysfunctional democracy and its attendant handmaiden Fourth Estate that not only did this happen, but it won't even be reported.
It doesn't matter what we think. It doesn't matter what we want. It doesn't even matter what most of our MPs do either.
The One Ring has called and the Nazgul are answering their master's call.
Thursday, April 21, 2011
ASI Blogger's Bash

I will, along with numerous other libertarian type bloggers, be attending the 'Bloggers Bash' at the Adam Smith institute tonight.
Details are here
If you're coming and we don't already know eachother in person please do come and say hi. I'll be the scruffy dodgy looking one who you might mistake for a long haired stunt double for Frodo Baggins. My secret night time vigilante identity is 'the incredible hobbit'.
No I haven't been drinking. Yes I will be tonight. :)
Thursday, April 14, 2011
Crushed
 Looks like LPUK (the Libertarian Party of the UK) has become nothing short of a full on liability to have anything to do with.
Looks like LPUK (the Libertarian Party of the UK) has become nothing short of a full on liability to have anything to do with.Read the whole distressing and profoundly disappointing story over at Anna's place.
Aside from feeling completely crushed by this I think it also goes without saying that I won't be renewing my membership of the party.
What a complete and utter tragedy for both Anna and family and the hopes,dreams and energy of everyone who got involved with the party.
Thursday, February 24, 2011
UK Customer Service - get things done by "promising not to use offensive language"
 This is a story for everyone (probably meaning all of you) who have been on the receiving end of appalling customer service, possibly involving an endless problem with no solution in sight.
This is a story for everyone (probably meaning all of you) who have been on the receiving end of appalling customer service, possibly involving an endless problem with no solution in sight.Here is a solid gold rant from a friend of mine on such an issue with Virgin Media regarding internet bandwidth that, owing to its ferocity looks like it might actually achieve something as long as he "promises to not use offensive language in future". This might be the future model for us consumers in the modern age of de rigeur bureaucratic resistance.
Also of great interest is the fact that his very angry email was sparked by the fact that Virgin Media apparently place close attention to comments made about them on Twitter. The Virgin staff watching Twitter contacted him after noticing angry tweets condemning their service.
After being invited to phone a particular member of staff directly to deal with his issue, he was further reprimanded for "offensive language" for referring to the staff he had previously dealt with as "lackeys", leading to him writing in his conclusion that:
 "To be honest, this wound up being one of the most surreal conversations I think I’ve ever had with a living breathing human being. At one point, I briefly considered whether or not this could be some sort of prank, the sort of pseudo-comical prank call the Fonejacker or a radio station might make, but even then it was simply too imaginative, too ludicrous for that. Instead, the insanity can only be the reality - that this genuinely was the way Virgin Media dealt with angry customer complaints, like an offended schoolteacher telling you off for using the word tits in front of the girls."
"To be honest, this wound up being one of the most surreal conversations I think I’ve ever had with a living breathing human being. At one point, I briefly considered whether or not this could be some sort of prank, the sort of pseudo-comical prank call the Fonejacker or a radio station might make, but even then it was simply too imaginative, too ludicrous for that. Instead, the insanity can only be the reality - that this genuinely was the way Virgin Media dealt with angry customer complaints, like an offended schoolteacher telling you off for using the word tits in front of the girls."If that resonates with any of you, I highly recommend you read the entire rant, complete with the angry email he sent where he blew his top.
Wednesday, February 23, 2011
Sunday, February 20, 2011
The song you should hear whenever they speak
It has now reach the point for me that whenever I hear British officials, Eurocrats or climate catastrophists speak, alarming us with some new supposed crisis or other, all I can hear in my head is this song. I find it a great palliative and recommend its regular use:
Monday, February 14, 2011
Why did Assange make his stand in the UK and not Sweden?
Lots of people have been openly wondering about this, including me.
If this video is to be believed then there is a list of reasons as long as your arm that would make any rational person in Assange's situation stay well out of Sweden's reach.
Just as one example, you could just stop at the fact that Karl Rove is advising the Swedish government - yes that Karl Rove, who's attitude to an underling who wouldn't follow the party line was to say "We will fuck him. Do you hear me? We will fuck him. We will ruin him. Like no one has ever fucked him!". The same Karl Rove who appeared to be instrumental in punishing Senator Jo Wilson in nakedly political revenge, for him casting doubt on the case for Iraq's possession of WMDs, by outing his wife, Valerie Plame. Valerie Plame who was at the centre of a CIA operation monitoring Iran's WMD programmes; with part of the fall out being that the CIA estimated it had set them back 10 years in their monitoring of Iran's putative ambitions.
If this video is to be believed then there is a list of reasons as long as your arm that would make any rational person in Assange's situation stay well out of Sweden's reach.
Just as one example, you could just stop at the fact that Karl Rove is advising the Swedish government - yes that Karl Rove, who's attitude to an underling who wouldn't follow the party line was to say "We will fuck him. Do you hear me? We will fuck him. We will ruin him. Like no one has ever fucked him!". The same Karl Rove who appeared to be instrumental in punishing Senator Jo Wilson in nakedly political revenge, for him casting doubt on the case for Iraq's possession of WMDs, by outing his wife, Valerie Plame. Valerie Plame who was at the centre of a CIA operation monitoring Iran's WMD programmes; with part of the fall out being that the CIA estimated it had set them back 10 years in their monitoring of Iran's putative ambitions.
Tuesday, February 01, 2011
The Mystic Met Office - the 'forecasts that are not forecasts'
 Autonomous Mind has just published further information on the Met Office story, showing that in internal discussions, the Met Office's 'forecasts that were not forecasts' were nethertheless referred to numerous times as forecasts. As AM puts it, "The Met Office logic is that although it quacks like a duck and walks like a duck it is actually a horse."
Autonomous Mind has just published further information on the Met Office story, showing that in internal discussions, the Met Office's 'forecasts that were not forecasts' were nethertheless referred to numerous times as forecasts. As AM puts it, "The Met Office logic is that although it quacks like a duck and walks like a duck it is actually a horse."There's lots of spin going on here, however there is no avoiding the fact that the 'forecast that was not a forecast' was used by the National Grid to determine their winter preparedness report, as I pointed out on Friday. They apparently didn't even have access to the now notorious "secret" report (the "secret" adjective originating from the BBC's Roger Harrabin).
The Mystic Met Office has now responded to the Register's inquiries on this issue, stating that it "has never suggested that we warned cabinet office of an 'exceptionally cold early winter'." - thus throwing Harrabin immediately under the bus.
Harrabin's response? Now that is another interesting story in and of itself. He claims: "This doesn't match a more conclusive forecast I gleaned from a Met Office contact in December" .
So what is this "more conclusive forecast" and who gave it to you Roger?
I note that he is also not paying attention when he says: 'I note a blog report (which I cannot yet verify) saying that a civil servant commented: "The Met Office seasonal outlook for the period November to January is showing no clear signals for the winter."'
Roger, that "comment" is clearly visible in the FOIA material I received, amongst the email traffic. It's more than just a "comment", it is the government outlining its official position, with which the Met Office appears to agree in its return email.
On that particular point Roger, it leaves a striking odd one out. You.
There's also another deception in play here. Harrabin goes on:
'A spokesman for the Cabinet Office told me they had passed the forecast to key stakeholders ("Government departments, local council as appropriate - we don't have a list").' [My emphasis]
 Are we really to believe that the "key stakeholders" didn't include the National Grid? (Not that it would have helped much anyway).
Are we really to believe that the "key stakeholders" didn't include the National Grid? (Not that it would have helped much anyway).You may be wondering why I highlighted that word. Here's another clue:
Both Autonomous Mind and the Register articles highlight a claim found in the Mail:
"Last night the Met Office confirmed it had passed on the advice, but a spokesman denied that withholding it from the public was motivated by embarrassment.
‘We did brief the Cabinet Office in October on what we believed would be an
exceptionally cold and long winter,’ she said."
Whilst Roger Harrabin is definitely not off the hook - and neither, if the veracity of the Mail's source is to be believed - is the Mystic Met Office, there is another underlying cultural problem:
The use of 'spokespeople'. These are used so often that it now drifts into the background consciousness for most of us, most of the time. Yet it is an extremely insidious propagandistic technique. The use of an anonymous spokesperson gets the organisation, or person, they are representing off the hook. There is no chain of accountability and any statements they make can easily be dismissed in the future.
The fact that both the Met Office and the Cabinet office are deploying spokespeople on this issue concerns me. It means we're not going to get to the actual truth without some serious hard work and implies that someone definitely does have something to hide, even if it is just their own bumbling incompetence.
Whenever this occurs journalists should immediately insist on knowing the identity of the person providing the information. Of course they don't, because they want easy copy, and access to the source of that copy. So it's up to the rest of us to apply the pressure and ask, every single time, who? The reasons why this is such a pressing issue are described eloquently by Heather Brooke in her excellent new book, 'The Silent State':
"Official spokespeople are powerful because they speak for the powerful; anonymity means they can exercise that power without being held individually accountable for it....When a 'spokesman' makes an accusation or spreads a smear, what recourse is there for the target? Anonymising spokespeople suits some journalists because if every source is simply a 'spokesman' or 'official', then it's easy to make up any old quote to suit your story.....As long as secrecy and anonymity reign, public sector bureaucracies will bethe hiding places for the incompetent, lazy and corrupt"
And if that doesn't hammer the point home enough, try this summation from Brooke:
"...we cannot be an informed electorate without access to information and a right to hold officials to account. And if we're not an informed electorate then we cannot call ourselves a democracy." [Emphasis mine]
This use of selective anonymity also has the potential to inflict very real damage beyond just the nature of our democracy:
"...special advisers and spin doctors operate a principle of never admitting a fault. can't we be treated by our leaders as grown-ups? Spin is costly for taxpayers because small problems aren't acknowledged, they are spun into successes or stifled until they reach a magnitude of catastrophic proportion."
And we've just seen this principle in action with regard to the Met Office, the government and the BBC:
 Due to yet another year of officially sanctioned lack of preparedness, chaos, suffering and likely unecessary deaths, have occurred. The game of pass the blame parcel will be no comfort to those identified by Anna Raccoon as on the receiving end - "Those pensioners found frozen solid in their front garden, the scenes of half starved refugees huddled against the cold at Heathrow airport, the two kilometre long lines of frozen travellers queuing round the block at St Pancreas Station, the double dip recession caused by the ‘extreme weather’"
Due to yet another year of officially sanctioned lack of preparedness, chaos, suffering and likely unecessary deaths, have occurred. The game of pass the blame parcel will be no comfort to those identified by Anna Raccoon as on the receiving end - "Those pensioners found frozen solid in their front garden, the scenes of half starved refugees huddled against the cold at Heathrow airport, the two kilometre long lines of frozen travellers queuing round the block at St Pancreas Station, the double dip recession caused by the ‘extreme weather’"All of which no one is willing to take responsibility for as the parties at risk of having to take it are hiding behind 'spokespeople' already. This looks like a tough battle ahead to pin down who is responsible, who is telling us the truth and who is lying.
And its a battle - yet another - only being fought in earnest by the 'fifth estate' of the blogosphere, with little assistance from the 'fourth estate' as they languish in the doldrums of increasing irrelevancy and distant relationship to the truth.
But fight it we will.
Friday, January 28, 2011
The Revealed Mystery of the Mystic Met Office

I have just received the Met Office's "secret report" and email correspondence with the Cabinet Office from a FOI request I made three weeks ago. The information they contain is quite significant and I hope others who have been working hard highlighting this issue such as Autonomous Mind and James Delingpole will find the following addition useful. God knows this is an extremely serious issue and the only people who appear to have been digging into it have been the bloggers (AM's investigation and analysis can be found here, here and here).
At the turn of the year we heard the revelation that, following an absolutely brutal start to the UK winter, the Met Office had allegedly warned the government in a "secret report" to expect such.
The Met Office also claimed that, in part because of the ridicule it had suffered for completely out of sync seasonal forecasts previously, it did not share this information with the public. It attempted to throw the government under the bus by claiming that the Cabinet Office had been informed, implying that it was central government's fault that the country was so unprepared and nothing to do with the Mystic Met Office's computer models with built in warmist bias that is perpetually out of touch with reality as a result.
It was Roger Harrabin, one of the BBC's chief climate alarmists, who originally claimed that the Met Office had issued this "secret warning". He said: "The truth is it [The Met Office] did suspect we were in for an exceptionally cold early winter, and told the Cabinet Office so in October. But we weren’t let in on the secret. The reason? The Met Office no longer publishes its seasonal forecasts because of the ridicule it suffered for predicting a barbecue summer in 2009 – the summer that campers floated around in their tents.”
I find it utterly pathetic that such an allegedly august institution can hide behind the excuse of fear of ridicule. It would be funny, self-satirising material were it not for the fact that, as a result of their influence, many people have died and suffered. That's not to mention the hole made in our economy and damage to tourism and international standing. Visitors, and those observing from abroad, perceived the lack of preparedness, especially at the airports, as akin to third world levels of disorganisation. They were right.
This is an extremely serious issue and so far no one appears to have been held culpable, not least in part to the (as per usual) relative silence of the mass media.
I immediately sent Freedom of Information requests to both the Cabinet Office and the Met Office, asking for copies of this "secret report" and any related correspondence after initially reading the story.
The essence of the Met's "secret report" has already been revealed by Bishop Hill who was able to obtain a copy before me; revealing it in all its simplistic glory (and showing clearly that the Met Office has been completely dishonest on this issue). It was reported over at Watts Up With That, and was quickly neatly eviscerated by the commentators.
They have also been claiming that paying customers receive more extensive information than the public. The "public" information mostly consisted in this probability map, which claimed, to quote AM, an "80% probability of warmer than average temperatures for November, December and January for Scotland and a 60-80% probability of the same for Northern Ireland, Wales and most of England."
As you will see from the link below, the special information released to paying customers, which apparently constituted their "secret warning" of a harsh winter is a complete joke and comes across like something written by a child.
 You can see for yourself that the Met Office actually predicts a slighty higher chance of a "cold" winter, rather than a "near average" or "mild" winter. This is based on a series of probabities out of 10. It boggles the mind that aside from the tiny amount of actual prediction in the report that this is the output of their energy-guzzling, multi-million pound supercomputer.
You can see for yourself that the Met Office actually predicts a slighty higher chance of a "cold" winter, rather than a "near average" or "mild" winter. This is based on a series of probabities out of 10. It boggles the mind that aside from the tiny amount of actual prediction in the report that this is the output of their energy-guzzling, multi-million pound supercomputer. On the next page they quantify what these terms might mean, but even here they are completely out of sync with what we actually experienced - for "cold" it meant "typical lower and upper limits" of temperature ranging from -1.5 to 0.4 degrees Celsius.
Further, the email correspondence is enlightening between the Met Office and the government:
Someone at the Cabinet Office wrote to the Met Office to tell them what the official position would be: "The Met Office seasonal outlook for the period November to January is showing no clear signals for the winter". The Met Office writes back - "That is fine." - also note the first mail sent my the Met Office, these are their "initial thoughts" (!)
So, as if the "secret" prediction wasn't awful enough, any claim that the Met Office actually warned the government of an impending harsh winter, and by implication that the government therefore did not act responsibly is a 100% complete and utter lie.
However there is more to this story that really needs to be aired. Not only have local councils been complaining of the complete failure of the Met Office to warn them, but even more seriously, the National Grid of all organisations, was flying completely blind too. See the National Grid's Winter Outlook document. Skip to page 7. The Grid obviously never received the "secret report" (not that it would have been much use anyway). They had to get their information from - the website! The same website that promised the 60-80% likelihood of a warm winter and which the Met Office has told us plebs we should ignore.
Largely as a result of this, the predictions for maximum demand were out by nearly 1 GW on the closest match to a horrifying 4.7 Gigawatts on the worst (information from NETA):
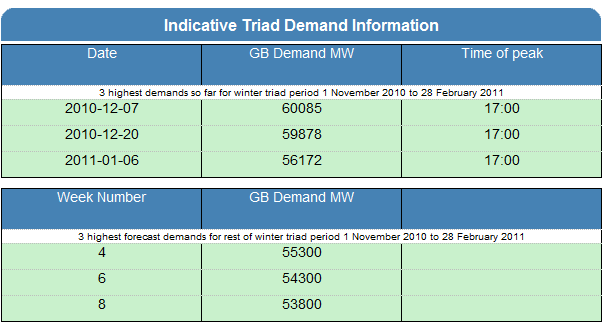
Had we not been able to buy approximately 2GW of power from France across the channel interconnector and ramp up the domestic production there could have been a serious outage. In a few years, thanks to complete government intransigience on our future power supply, we won't be able to repeat the feat and of course there are no guarantees that the French will always be able to sell us that much energy when we need it. When the total demand goes up to close to 60GW, in still winter conditions, the 3000+ wind turbines installed provide an incredible 0.1% of our power needs. That lunatic Huhne seems to think our power issues will be solved by the costly build of another 10,000 turbines. So in similar conditions that "capacity" will provide approximately 0.4% of the power supply, just when we need it most. Outstanding, no?
By the way, Browned Off's comment to me is well worth a read. He corrected me on the relative positions of the government, EU and energy industry on this. It certainly seems plausible - the government is happy for the EU to take most of the blame for something that - at root - is its own fault. It fits perfectly into the singular principle that defines modern British politics - expediency.
Unfortunately the combination of this political expediency - at the expense of our national power supply - and the religious convictions of the warmist-infested Mystic Met office are going to result in many more deaths and suffering. There have already been needless deaths and suffering thanks to both.
These people have gone from being an annoyance to an active menace, and no one appears to be holding them to account.
Anyway, here are the files, including the email correspondence and the "report".
Subscribe to:
Posts (Atom)